
今天我們來聊聊 增強式學習 (Reinforcement learning),一個最近也很 “潮” 的演算法。
自從 Alpha Go擊敗人類後開始,大家開始重視增強式學習演算法的能力,沒想到能透過一個 Deep learning 、 Machine learning的演算法,能擊敗最強的圍棋手。有興趣的話 Netflix 有 AlphaGo的紀錄片,大家可以參考看看。

[source: Google DeepMind]
主要概念為視 "環境" 執行 "動作",並期望得到最佳收益或者利益。其核心概念就是 trial & error!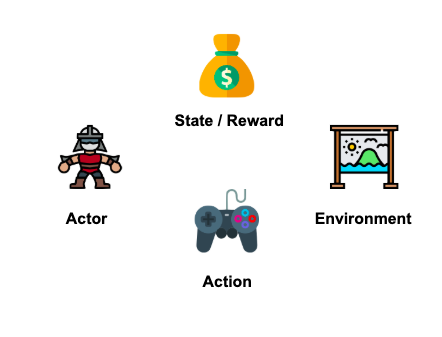
由 Actor / Action / (State / Reward) / Environment 所組成。
而增強式學習主要有四個元素
我們來簡單summary一下,強化學習建立一個 agent ,並與environment互動從中學習。每次action後,agent都會收到reward 與 下一個state。
最直觀的應用案例就是 - 打電動 ! 下連結為 使用 RL 玩 馬力歐,會不斷的 trial & error 。
Reinforment Learning (RL) 有許多種演算法。主要分為三類 Policy based / Value based / Model based。都可以依名字來了解他們所想要 Focus目標。
這次我們會Focus 在 DQN,將 Deep learning 應用在 Reinforement learning 。簡稱 DQN。
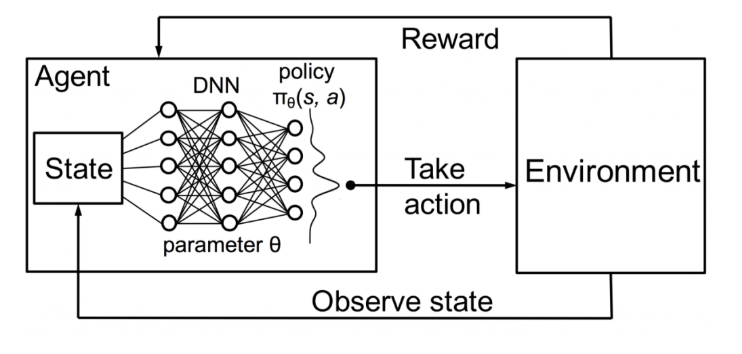
首先我們要先說明一下 Q-Table,在執行 RL的過程。會儲存一個 table ,記錄特定狀態下,執行所有動作以及所產生的value。通過這個table,可以找出最佳的執行方法。在 DQN中,將 Q-Table的 的設計轉成使用一個 神經網路來學習。透過 神經網路的學習,搭配不同的layer,可從環境中,提取龐大的特徵來學習。
增強式學習也是個機器學習的突破,不像是過去監督式學習的方式還要去 Label 資料,透過設定的 agent 、 value function 、 environement 等,就可以學習。因此,當其他模型無法進步,或者其他模型怎麼都train不好,或許該是使用增強式學習來硬train一發!
今天簡單介紹了 RL 的演算法,明天我們一樣用 tf 2.0 來實作 RL 。明天連假結束了,有種淡淡的哀傷 ~
大家明天加油!

